In Luma Health, often times we have to do queries against collections that have 50, 60, 100M+ records — as you’d expect, well thought through queries and good indexes are the building blocks to querying these types of collections.
In today’s example, we had a collections in production that contains a DATE field where we have to do range queries (e.g. DATE > something, DATE < something). We started to notice a large number of the underlying API calls that hit that table were getting logged to our slow execution monitoring. Specifically in one service, we started seeing about 500 slow logs per 5 minute interval.
We spent some time looking through the Mongo query planner, digging in to the DB queries the API calls were making and and few found a few examples like this:
date: { $lte: endDate },
endDate: { $gte: startDate }Now both the date and endDate fields were in a proper compound index that the Mongo query planner was using, but when looking through the execution stats, the query planner was canonicalizing each end of the ranges as date: {$lte: endDate, $gte: Infinity }. Yikes! All the hard word in indexing, query design, etc, went out the window — when the query executed, Mongo had to pull two entire ranges and then intersect them in memory rather than through the index.
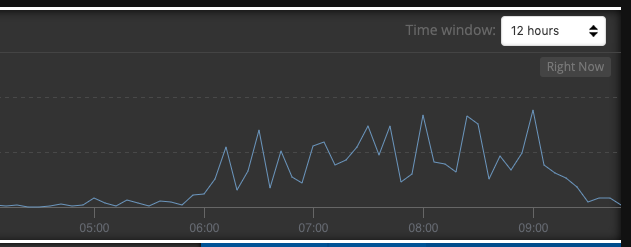
We quickly fixed the queries and as you’d expect, much happier production monitoring. In the graph below you see around 6am the daily load starts to pick up and the the slow logs pick up in frequency. We deployed the change about 915am and like magic, the slow logs go back down to zero.
Moral of the story: unbounded range queries can lead to very unintended performance consequences.